Zero-shot Sentiment Analysis using Llama 3.2
2024-10-14
In this post, I go over zero-shot sentiment analysis using Llama 3.2. First, I wanted to find a good dataset. I went to browse Kaggle datasets and came across this dataset.
The dataset contains user reviews of the Spotify app on Google Play Store.
I love Small Language Models. I can run them on relatively low GPU requirements or even on CPU without worrying too much about how slow it's gonna be, So I wanted to compare both Llama 3.2 1B and 3B on zero-shot classification on this dataset to get a feel of how well they perform and follow instructions. I use the lovely Ollama API to interact with these models.
The dataset comes in a single CSV file with two columns: Review and label.
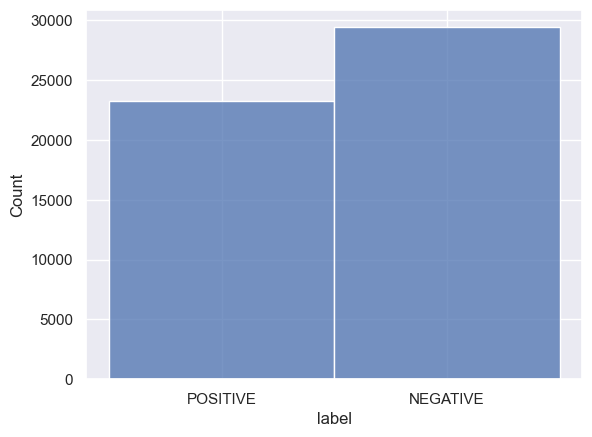
Here's the distribution of label
Here are all the imports we're gonna need:
Since I just want to get a feel of how it works and don't really have time to run on all 51K examples in the dataset, I sample I small subset of it.
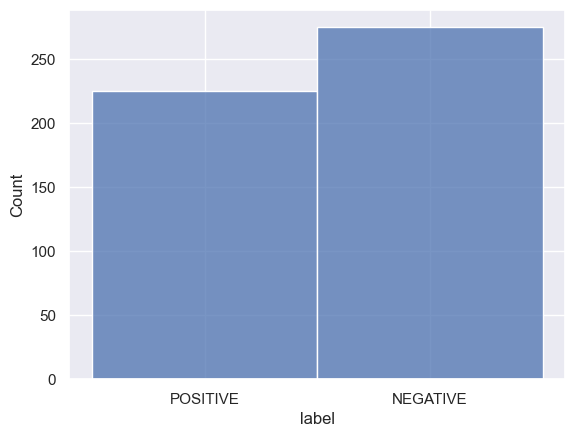
Here's the distribution of label in the sample
Then I define num_samples to be the length of my final dataframe
I define two prompts to compare between them
I define a helper function that returns either POSITIVE, NEGATIVE, or FAILED in case the response wasn't either POSITIVE or NEGATIVE. (This can happen if the SLM doesn't strictly follow our instructions).
Then I run a loop going over each model, each prompt, and each sample to run prediction.
I define a class that will hold relevant stats.
Then I compute these stats:
Now, I can print all the collected results in a nice format:
And this produces:

We can see prompt_2 is producing slightly better results that prompt_1.
We can also see that the 3b model is consistently outperforming its 1b sibling, and both of them don't follow the instruction very rarely.
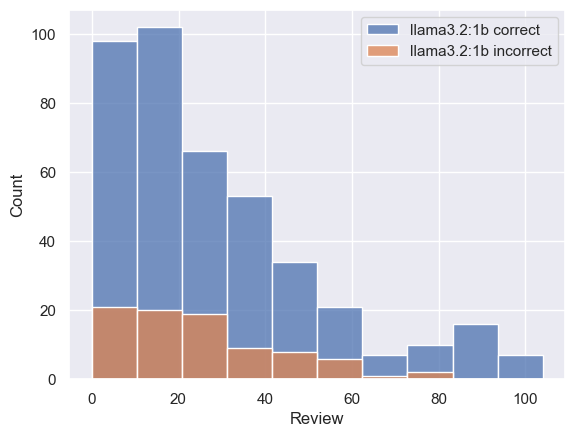
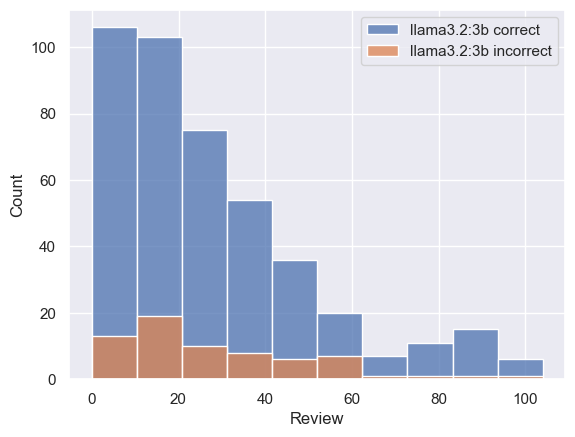
Here's some anallysis on some correct vs incorrect predictions on different sequemce lengths
Here's a link to the GitHub repo that has the code.